
今回は、ファイルの読み書きを行う方法について説明します。
といっても、ファイルの読み書きはパソコン上で手作業でもできますし、 日常的に行っているという方も多いかもしれません。 なので、あまり新鮮味が無いかもしれませんね。
そこで、今回はせっかくプログラムでコンピューターを制御してファイルを読み書きするので、 ついでに「 ファイルがコンピューター内のどこに、どういう形で保持されているのか 」といった点についても一緒に押さえておきましょう。
これまで、値をメモするのに使ってきた「 変数 」ですが、 その値を読んで使えるのは、プログラムの実行中だけです。 実行が終わって閉じた後に、 「 さっき実行したプログラムの変数 『 x 』 の値を読み出したいんだけど… 」 と思っても、ふつうは無理です。
一応、実行終了直後なら、特殊な方法まで含めれば絶対無理とまでは言い切れないのですが (※セキュリティ面で問題になったりします)、 別のプログラムを何個も実行したり、コンピューターを再起動した後になると、もう絶望的です。
なぜでしょうか。 ここで「 変数と配列 」の回の話を、少しふり返ってみましょう。 コンピューターには、値をメモするための部品として「 メモリー 」が搭載されているのでした。 変数は、そもそもメモリーを簡単に使うためのものでしたね。 実はこのメモリー自体が、あくまでも「 コンピューターの動作中に、一時的に値を記憶する 」事を想定した部品なのです。 なので変数も、やはり一時的なメモ用の機能であり、実行終了後に値を読み出すような事を想定した機能にはなっていないのです。
なお、このメモリーは、少し専門的な呼び方では 「 主記憶装置 」、英語で「 Main Memory ; メインメモリー 」 と呼びます。 他にも「なんとかメモリー」と呼ぶものは色々あるのですが、 プログラミングで単にメモリーと言うと、ふつうはこのメインメモリーを指します。 このコーナーでの、これまでの説明でもそうでしたね。
さて、プログラム終了後や電源を切った後でも、ずっとデータを覚えておいてほしい場面も多いので、 もちろんコンピューターにはそのための部品も入っています。 それは一般に 「 ストレージ 」 などと呼ばれます。 ストレージは英語で 「 Storage 」 と書き、これは日本語で「 貯蔵 」といった意味です。データの貯蔵庫ですね。 こちらは、専門用語では「 補助記憶装置 」と呼ばれます。

なお、ストレージは、後で説明するハードディスクという機械の略称として、「 ディスク 」と呼ぶ人も結構います。 ただし、CDやDVDなどもディスクと呼んだりするので、混同には注意が必要です。
ところで、「 データを覚えておく 」という目的は同じなのに、メモリーとストレージで、なぜわざわざ別々の部品が必要なのでしょうか? それは、 一言で「 データを覚えておく 」 と言っても、 実際にそれが可能な電子部品や機械には様々なものがあり、それぞれ得意・不得意がある ためです。 コンピューターはそれらを適材適所で組み合わせて使っているので、メモリーとストレージが別々の部品としてあるのです。
メモリー(メインメモリー)は、変数などのように、計算中の一時的なメモのために使われるため、とにかく読み書きのスピードの速さが重要です。 なぜなら、コンピューターの頭脳であるCPUが計算するスピードはとてつもなく速いので、 値をメモする事にもたついていたら台無しだからです。 また、それだけとてつもない速さでメモとして使われるという事は、膨大な回数の読み書きに耐えられる耐久性も必要になります。 メモリーには、このような要求に適したものが使われます。

たとえば2021年時点のコンピューターに搭載されているメモリーは、ふつう DRAM という半導体素子が使われています。 これは確かに読み書きが高速で、使用回数に対する耐久性も非常に高いという特徴があります。 また、実はCPUの中にも「 キャッシュ 」と呼ばれる小さなメモリーが入っているのですが、 それにはさらに高速な SRAM というものが使われていたりもします。 しかし、DRAM や SRAM は電源を切るとデータが消えてしまう( 揮発性 ) という性質があり、ストレージには不向きです。
個人向けのコンピューターのストレージには、「 電源を切っていても、ずっとデータが残る( 不揮発性 ) 」事が重要です。 また、コンピューターを長く使っているうちに、データがたまりすぎて足りなくなると困るので、価格あたりの容量が大きい事も重要です。 ストレージには、このような要求に適したものが使われます。

では、具体的にストレージの中身には、どんなものが使われるのでしょうか。
それは時代によって変化しますが、 特に近年主流になりつつあるものとしては、 NAND型フラッシュメモリー(以下、NANDフラッシュ) が挙げられます。 名前にメモリーと付いていますが、これまでの話におけるメモリー(メインメモリー)ではなく、ストレージ用に使われます。 半導体素子の一種ですが、DRAMとは違い、電源を切ってもデータが消えないという特性を持っています。 半面、読み書きのスピードや、書き換え回数の耐久性では、DRAMにはかないません。
NANDフラッシュと書くとずいぶん専門的な雰囲気がしますが、実はみなさんおなじみの、USBメモリーの中身です。 カメラや携帯電話・スマートフォンなどに使う各種メモリーカードの中身も、ほぼNANDフラッシュです。実はとても身近なんですね。
と言っても、コンピューターのストレージ用には、USBメモリーなどを大量に常時接続して使うのは不便なので、「 ソリッドステートドライブ( SSD ) 」という、箱型やカード型の部品にして使われます。 中にはNANDフラッシュのチップをたくさん並べて搭載されていて、大容量を実現しています。
もう一つ、ストレージとしてよく使われるものに、「 ハードディスク 」というものが挙げられます。 ハードディスクは結構昔から使われてきたもので、現在もかなり大容量の製品が安価に買えます。 中身は、回転する磁気ディスクが入った精密機械です。 そのため衝撃に注意する必要があったり、機械的な寿命などもあったりしますが、一方でデータの書き換え回数に関する耐久性の高さや、電源OFFの条件下におけるデータ保持期間の長さなどの長所があります。
さて、メモリー( メインメモリー )への値の読み書きを、簡単にしてくれるのが 「 変数 」 でしたね。 それと同様に、ストレージへの読み書きを、人間にとってわかりやすくしてくれる、「 ファイル 」というしくみがあります。 「 あります 」というか、みなさもよく知っているかもしれませんね。 ここでいうファイルというのは、ふつうにコンピューターを使っているときにも登場する、あのファイルの事です。 そう、たとえばみなさんがコンピューターで文章を書いてファイルに保存したり、開いたりしたとき、実はコンピューターはストレージにデータを読み書きしていたのです。
結局のところ、コンピューターは 1 と 0 の世界で動作しています。 ストレージも、ただ膨大な数の 1 と 0 の列を記録しておける装置でしかありません。 その中の、どこからどこまでの範囲に、どのデータが保存してあるかという事を、人間が直接管理するのは大変です。 そこで 「 ファイルシステム 」 というものが、わかりやすく仲介してくれて、その結果、人間にはファイルという形で見えているのです。
たとえば 「 ストレージの 10111010 番地から 11101011 番地までにデータを書き込みます 」 といったやり取りは、つらいですよね。 ファイルは、こうした「 ストレージ内でのデータの場所 」を、人間にとってわかりやすい「 名前 」という形でおきかえてくれます。 それによって、「 『 今日の作業内容 』という名前のファイルにデータを書き込みます 」 というように簡単にストレージを使えるわけです。 これは、メモリーのアドレスと、変数の名前との関係に似ていますね。

また、「 ストレージに記録されている 1 と 0 のデータが、何を意味しているものなのか 」というのも、大切な情報です。 たとえば、テキストエディタで作ったファイルなら、「 テキストを 1 と 0 になおしたもの 」です。 カメラで撮った写真なら、「 画像を 1 と 0 になおしたもの 」です。 いや、もっとなにか別のものだったかもしれません。 それを忘れると、どう解釈するべきか不明な、ただの 1 と 0 の暗号のようなものになってしまい、とても困ります。
そこで、ファイル名の末尾に、テキストなら「 .txt 」、カメラの写真の画像なら「 .jpg 」といったように、 中身を区別するためのキーワードを「 . 」記号区切りで付ける方式がよく使われます。 このキーワード部分は「 拡張子 」と呼ばれます。

この拡張子の部分を見れば、そのファイルの中身(1 と 0 の列)が何だったのかを判断できるわけです。
ここで、「 え?ファイル名にそんなもの付いていないぞ? 」 と思った方も多いでしょう。 それもそのはず、拡張子を表示しない設定になっているコンピューターも多いのです。 それは恐らく、ファイル名を書きかえる際に、ミスして拡張子を消してしまって、何のファイルか不明になってしまう事を防ぐためでしょう。 でも、プログラミングなどでコンピューターを深く使いこなすには、拡張子が見えない事が逆に不便な場面もあります。 そこで、表示させるように設定を変える事もできます。「 拡張子 表示 」などのキーワードで Web 検索してみてください。
なお、OSの種類によっては拡張子に機能的な役割がなく、ただの目じるしで、本当に拡張子が付いていないファイルが普通に存在する場合もあります( 拡張子以外にも、ファイルの中身を判断する方法があるためです )。
さて、いよいよ本題です。プログラムからファイルを読み書きしてみましょう。 そうすれば、データはストレージに保存されるので、プログラムの実行終了後も、コンピューターの電源を切った後も、ずっとデータを残しておく事ができます。
まずは、いちばん簡単な方法から試してみましょう。 変数の数だけファイルを作り、それぞれの変数の値を、それぞれのファイルに書き込んでみます :
ここで使っている 「 save ( セーブ ) 」 関数は、データをファイルに書き込むための関数です。 カッコ内には「 , 」区切りで、ファイル名と書き込み内容を指定します。上のように、書き込み内容を変数で指定する事も可能です。 その場合、変数の値が書き込まれます。
このプログラムを実行すると、「 file_i.txt 」 と 「 file_f.txt 」および 「 file_s.txt 」という名前の 3 つのファイルが、プログラムと同じ場所に作られます。 ( ※ ただし「 .txt 」の部分はテキストファイルを意味する拡張子なので、コンピューターの設定によっては表示されません。)

これらのファイルはただのテキストファイルなので、マウスでダブルクリックすると、テキストエディタなどで開けるはずです。 中には、それぞれの変数の値が、ちゃんと書き込まれています。 コンピューターの電源を切って入れなおしても、ちゃんと中身はそのまま残っています。
今度は、ファイルから変数に、データを読み込んでみましょう :
ここで使った 「 load (ロード) 」関数は、データをファイルから読み込むための関数です。 このようにカッコ内にファイル名を書いて、「 = 」記号の右で使えば、左の変数にファイルの内容が代入されます。 ただし、ファイル名はちゃんと拡張子まで含めて書く必要があります。 ここではちゃんと拡張子「 .txt 」を付けています。
( ※ コンピューターで拡張子が表示されない設定になっていて、読み込みたいファイルの拡張子がわからない場合は、 ファイルを右クリックして「 プロパティ 」などから調べる必要があります。詳しい方法は環境によります。 )
このプログラムの実行結果は以下の通りです:
このように、3つのファイルから3つの変数に、それぞれ値を読み込めていますね。
(※ ファイルの内容は文字列型のデータとして読み込まれ、変数に代入する時点で、その変数の型に変換されます。変換できない内容だった場合はエラーになります。 )
上で扱った save 関数や load 関数は、ファイルの中身全体をまとめて読み書きします。 でも、 1 行ごとに読み書きしたいという場合もよくあります。 たとえば、上で行ったように変数の値をファイルにメモしたい場合、 1 行につき 1 つの値を書くようにすれば、ファイルを 1 個ですませる事もできますね。
その代わり、行単位の読み書きでは、以下のように少し手順が増えます:
ちょっとめんどうですが、便利なので試してみましょう。まずは書き込みです:
詳しい説明の前に、まずは実行してみましょう。 すると「 file.txt 」というファイルが作られ、それをテキストエディタで開くと:
と書かれています。ちゃんと行ごとに書き込めていますね。
さて、順を追って説明しましょう。 まず「 open( オープン ) 」関数は、ファイルを開いてくれる関数です。 「 開く 」と言っても、コンピューターの内部で開かれるだけなので、画面上で内容が表示されたりはしません。 でも、開いたファイルにID番号を割りふって、「 = 」の左の変数( ここでは id )に代入してくれます。 これは複数のファイルを区別するための、名簿( めいぼ )の番号のようなものです。
open 関数のカッコ内の最初はファイル名を書きます。 その後に「 , 」記号で区切って 「 "w" 」とありますが、これは日本語で「 書く 」を意味する英語「 write ( ライト ) 」の 1 文字目です。 これにより、「 このファイルは書くために開きます 」とコンピューターに知らせています。 書くために開いたファイルを読む事はできませんし、その逆もできないので、注意が必要です。
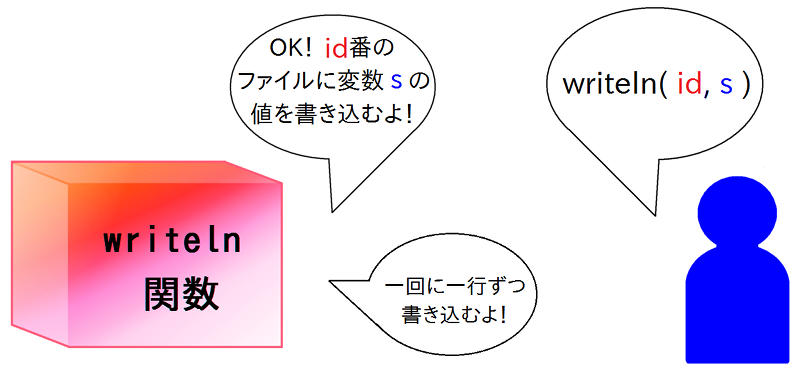
さて、いよいよ書き込みです。 「 writeln ( ライトライン ) 」関数は、ファイル内容を 1 行だけ書き込んでくれる関数です。 カッコ内の最初には、open 関数のところで変数に代入しておいたID番号を使います。 これは、仮にファイルが複数あっても、どのファイルに書き込むのかわかるように知らせているわけです。 その後は、書き込む行の内容を指定しています。 ここでは変数の値を書き込んでもらっています。
最後の 「 close (クローズ)」 関数では、ファイルを閉じています。 この処理は、見た目では何も起こらないように感じますが、忘れるとファイルが最後まで書き込まれなかったり、 他にもいろいろな点でよくないので、忘れないようにしましょう。
続いて、上で作ったファイルを 1 行ずつ読み込んでみましょう:
このプログラムの実行結果は以下の通りです:
このように、ファイル内容を 1 行ずつ変数に代入できている事がわかります。
最初に open 関数でファイルを開いている点は、先ほどの writeln 関数による書き込みと同じですね。 でも、open 関数のカッコ内の 2 つめの内容が「 "r" 」になっている事に注意してください。 これは日本語で「 読む 」を意味する英語「 read ( リード ) 」の 1 文字目です。 これにより、「 このファイルは読むために開きます 」とコンピューターに知らせています。 書き込みで使う「 "w" 」の逆バージョンです。
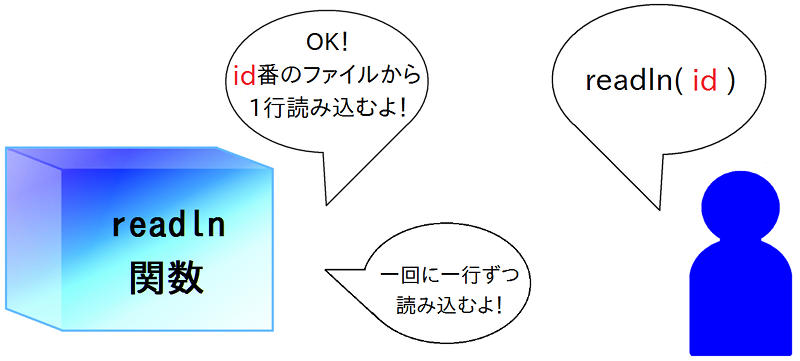
続いて読み込み処理です。load 関数はファイルの中身をまるごと変数に代入してくれましたが、 上の例で使っている「 readln ( リードライン ) 」関数は、 ファイルの内容を1行だけ読んで、それを「 = 」の左の変数に代入してくれます。 このように何度も続けて使うと、毎回 1 行ずつ、次の行へと読み進んでくれます。 なのでここでは、変数「 i 」にファイルの 1 行目、「 f 」に 2行目、「 s 」に3行目の内容が代入されるわけです。
最後に先ほどと同様 close 関数でファイルを閉じています。忘れずに閉じましょう。
さて、最後におまけです。 ファイルの読み書きでは、しばしば「 文字化け 」に出くわす事があります。 文字化けというのは、「 あれ、ファイルを開いて読んだら、書かれているはずの内容じゃなくて、意味不明な内容になってる? 」という現象です。 Webページなどでたまに見かけますね。 特にあるコンピューターで書いたファイルを、OSの種類が違う別のコンピューターで読み込んだ場合などに、よく発生します。
文字化けは、なぜ発生するのでしょうか。 それを詳しく理解するために、まず今回の序盤で説明した、ストレージとファイルの話をふり返ってみましょう。 ストレージはあくまでも膨大な 1 と 0 の列を覚えておく電子部品で、 それを人間にとって扱いやすい形で見せているのが、ファイルでしたね。 つまり日本語で書かれたテキストファイルであろうと、ストレージには 1 と 0 の列になおして記録されているのです。
論より証拠、たとえば先ほど書き込んだファイル「 file.txt 」の中身は:
でしたが、これを 1 と 0 の列のまま読み込んで、表示してみましょう:
すこし難しくなってしまうので、プログラム内容の細かい説明はやめましょう。 詳しく読む必要はありません。重要なのは実行結果で、以下の内容が表示されます:
( ※ 色を付けてある部分は「 あ 」の文字を表しているデータです。 ただし内容は環境によって異なります。 なお、各行の頭の「 0b 」の部分は、1 と 0 のデータに付く目じるしのようなものなので、無視してください。 )
これが、ファイル「 file.txt 」の中身を、 1 と 0 のまま読んだ中身です。つまりストレージに記録されているデータそのものです。 みなさんが、ふつうにコンピューター上でファイルを開くと、画面にテキストが表示されますね。 それは、内部でこのような 1 と 0 の列から、今度はテキストへと逆向きにおきかえて、なおされるからです。
そして、このようなテキストから 1 と 0 へのおきかえ方に、「 文字コード 」と呼ばれる複数の方式があるのです。 たとえば「 あ 」という文字は、 「 UTF-8 」という文字コードでは「 11100011 10000001 10000010 」におきかえられます。 一方で、「 Shift_JIS 」という文字コードでは「 10000010 10100000 」になります。 そう、同じ文字でも、文字コードによって別の 1 と 0 の列になってしまうのです。
では、たとえばUTF-8 の文字コードを使って書き込まれたファイルを、もし Shift_JIS が使われていると思って読み込んだらどうなるでしょうか? なんとなく想像できるでしょうが、やってみましょう:
このように、実は open 関数のカッコ内の最後に、読み書きに使う文字コードを指定する事ができます。 実行すると:
このように、書き込んだ「 あ 」とは全然違う文字として読み込まれた事がわかります。これが文字化けです。 そこで、open 関数のカッコ内で指定している文字コードを、 読み書きで両方とも "UTF-8" か "Shift_JIS" でそろえれば:
このように、書き込んだ通り「 あ 」として読み込めます。 つまり、書き込みと読み込みの文字コードは、同じものを使う必要があるわけです。
さて、open 関数のカッコ内に文字コードを指定しなかった場合、 標準的な文字コードが自動で使われます。 これは、他のプログラミング言語や、ソフトウェアなどでもよくある事です。 でも、実はこの「 標準的な文字コード 」というのが、OSの種類や時代、日本語・英語バージョンなどの環境によって、違ったりするのです。 これが、ファイルを別のコンピューターで開くと、よく文字化けしてしまう原因です。 そんなときは、ファイルを書き込むのに使われた「 文字コード探し 」をする事になります。 ここで扱った UTF-8 と Shift_JIS は特によく使われるものなので、この 2 つはぜひ覚えておきましょう。
また、文字コードと並んでやっかいなのが、改行( 行のおりかえし )を意味する 1 と 0 の列です。 先ほど 1 と 0 で表示してみたファイル内容で、3 回ほど「 0b1101 0b1010 」という部分がありましたが、 この部分がそうで、「 改行コード 」などと呼ばれます。 実はこれもOSの種類によって異なり、 テキストファイルの見た目がおかしくなったりする原因です。 readln 関数では、いろいろな環境の改行コードをふまえた上で、1 行ごとに読み込んでくれます。 読み書きの際に自分で細かく調整する事もできますが、ちょっとややこしいので、ここでは省略しましょう。
